Timezone correcting Fitbit sleep data
Published November 30, 2023
Hello, dear Reader.
You’re probably here because you exported your Fitbit data so you could make some cool visualizations, and then realized that all the nights of sleep are recorded in device-local timestamps instead of UTC/GMT. I’m here to show you a way to convert most of that data to UTC so you can analyze it properly.
How do we know that Fitbit sleep data is not timezone corrected?
On the forums, someone claimed that Fitbit data exports in UTC timestamps . I can show this is not true. One way this is really visible is in the plot of my bedtimes recorded on my Fitbit — even though I've lived in Europe, Asia, and the US throughout this period, the actual hour which I go to sleep is always the same. If the bedtimes were UTC-adjusted, they would have distinct vertical shifts whenever I drastically move timezones.
My bedtimes, according to my Fitbit data
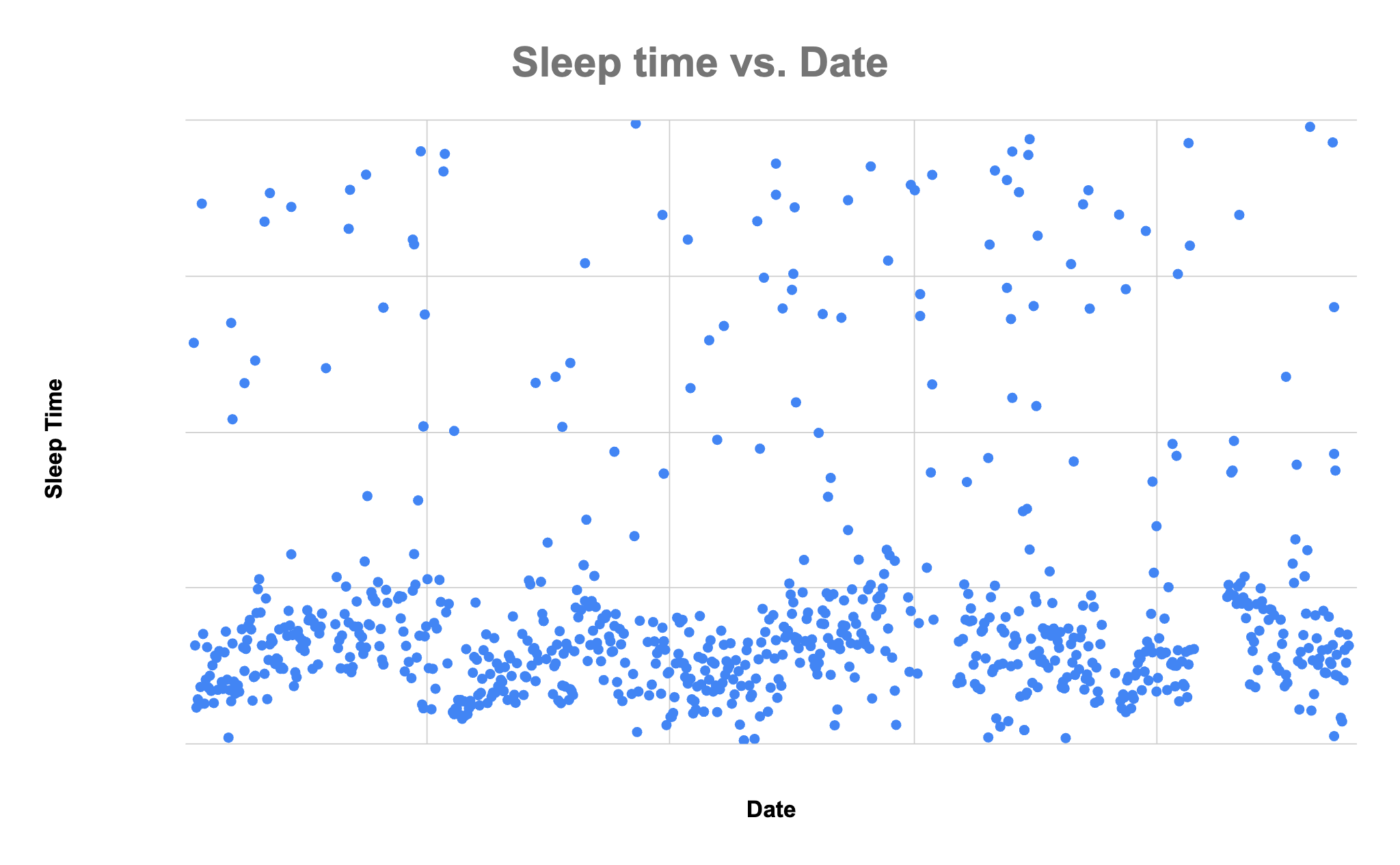
Here's another example. My sleep data from July 2021 have startTimes around 1-2am, and I was in Pittsburgh (EST, UTC-4) at the time. If the startTime were in UTC, I would have been sleeping around 10pm regularly, and I know for a fact that wasn't the case.
Raw sleep data in table form. The timestamps don't line up with UTC given my location at the time
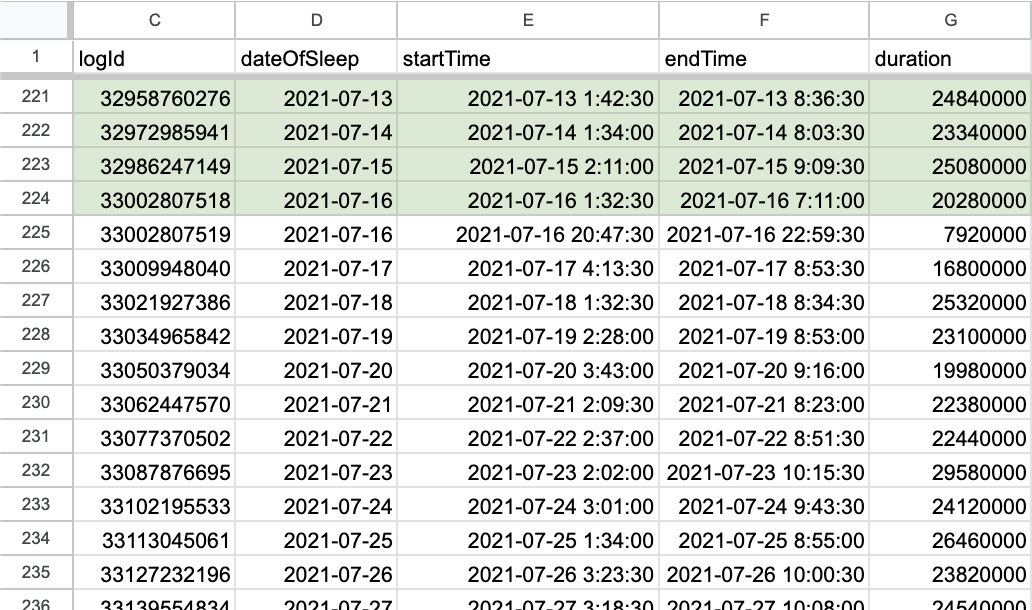
How do we fix it?
As I browsed through my agglomerated Fitbit data (details on how to do that here), I could only find sleep data that either shared local timestamps (useless), or were recorded 24/7 (impossible to sync w/ sleep sessions). That was until I looked at the Sleep Stress Score file.
Sleep stress data, aka our saving grace
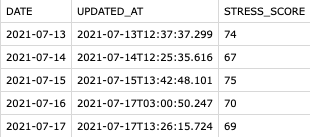
It looks like the STRESS_SCORE column is usually finalized right after waking up, meaning the UPDATED_AT column usually lists the time 1-30 minutes after a sleep session ends. But unlike the raw sleep data, the stress data uses UTC timestamps!!
Looking at July 13th, endTime=8:36 (local, UTC-4), and UPDATED_AT for the 13th is 12:37 (UTC). For the 14th, 8:03 and 12:25.
I looked at a few other random ranges as well, and the shift looked consistent. Bingo!
A few consecutive
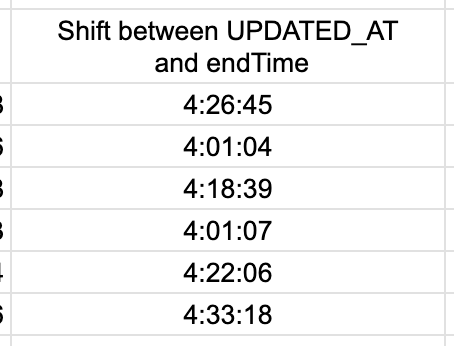
We just need to take each day of data in the stress scores and figure out which row of the sleep data it corresponds with. Then, we can timezone-adjust that row of sleep data, giving us UTC timestamped data that we can work with.
Refining the technique.
We naively match every stress timestamp with a sleep row, then subtract the stress timestamp from the endTime. This should give us the timezone offset of that sleep row, right? Nah!
Chart of wildly varying timezone offsets from subtracting stress UPDATED_AT and endTime
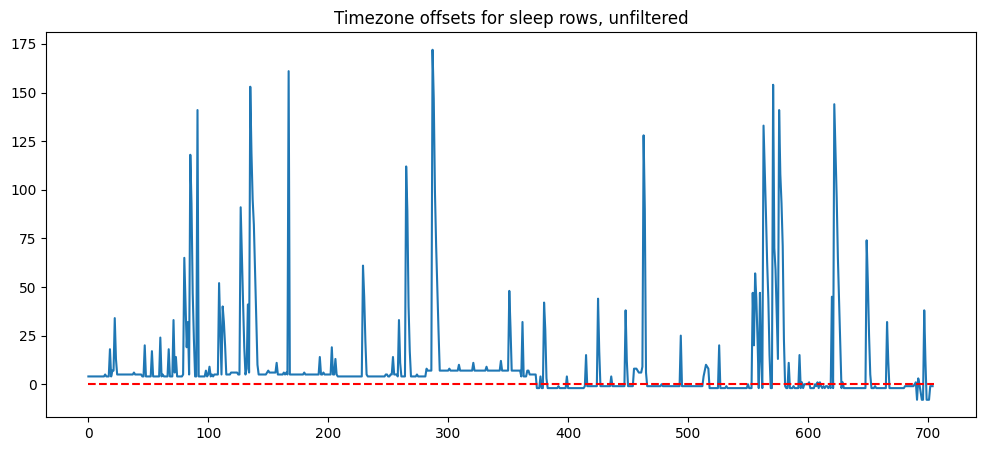
A ton of the offsets are higher than +12, which aren't valid timezones!
Since we are using the UPDATED_AT column, the stress score update can happen at any point after the sleep time ends. In my data alone, it can change up to a week later! If we use this as the UTC version of the endTime, we will end up with incorrect timezone offsets. This jankiness results from our unintended use of the stress data.
Naive filter
If we don't mind throwing out some bad data, an easy first filter is to throw out all data with offsets higher than 12. This gives us only the reasonable sleep rows
Timezone offset over the years, without the offsets over 12
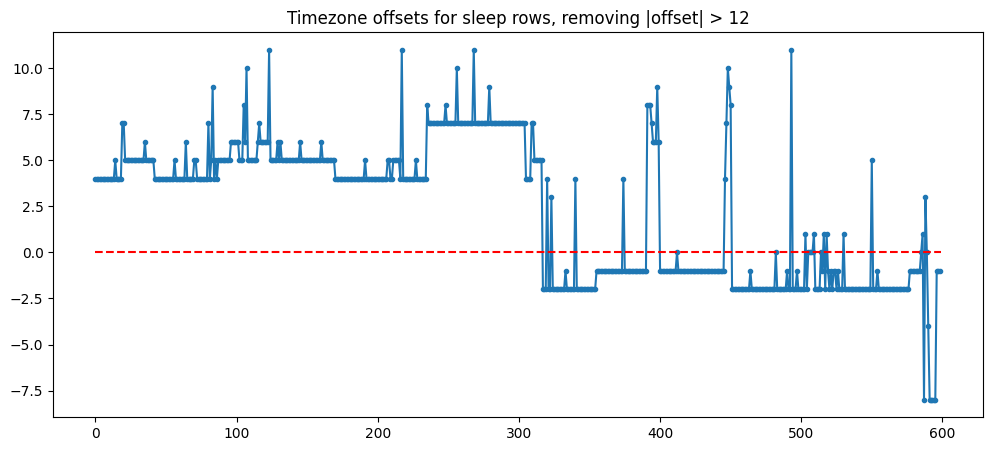
This is much cleaner, and you can clearly see the horizontal lines from when I lived in the same place for a while. But because we've removed some data, it's going to be hard to interpolate between points to fix the remaining noisy points — if a +1 shift lasts only a day, I'm not sure if I can just flatten it to its neighbors since I'm not sure its neighbors are actually just 1 day apart. And most offsets > 12 happened during a day of travel, so a spurious point is likely not equal to its neighbors and many will be thrown out.
Less naive filter
Instead of tossing out offsets over 12, I tried to keep as many points as I could from the beginning. Starting with full data, every single-day "spike" in time offset was set to its neighboring values (e.g. [4,5,4,4] -> [4,4,4,4])
Same chart as before but removing spikes only. The title is lying
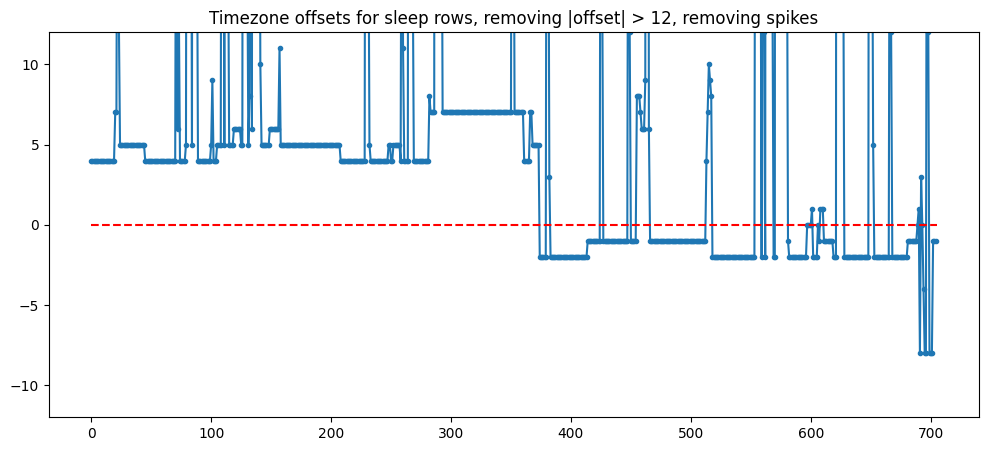
Then, I kept only the sleep rows that had a neighboring point that agreed. My reasoning was that once the sleep timezones become stable, timezone offsets can be corroborated with adjacent points.
2nd stage of filtering, removing spikes then only taking points that have an adjacent, equal point
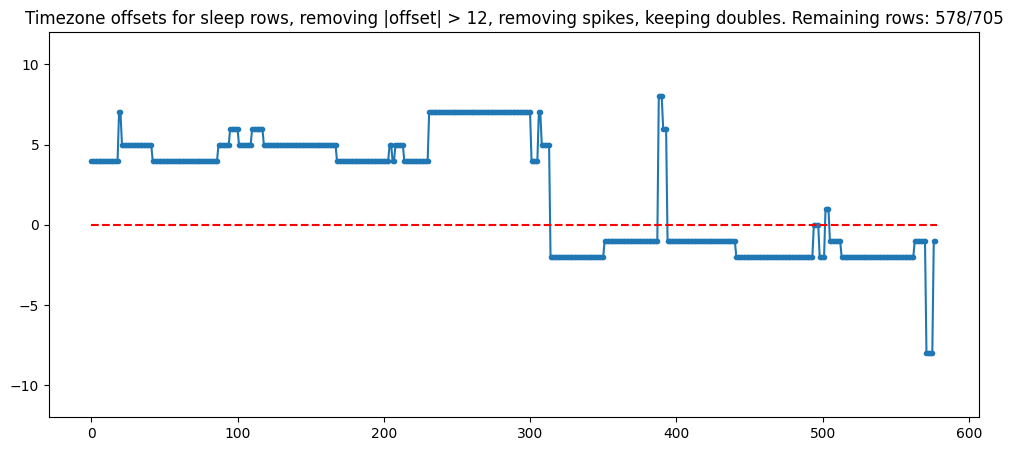
This operation does throw out some data points, but it's the end of my filtering process. We are left with roughly ~82% of the sleep rows, and fairly reliable knowledge of the row's timezone offset.
Message for Fitbit devs
Using only local timestamps for sleep data makes it incredibly hard to do proper analysis between your sleep data and other, real scientific data sources recorded using Unix timestamps, like my Tetris scores. This is a huge gripe of mine regarding Fitbit, I mean, how hard can it be to add a UTC-corrected column to the sleep .csv?
Conclusion
The code for the fitbit sleep data timezone correction can be found here: https://gist.github.com/kongmunist/a2ab8e7160ce9d540885b1fded08d13d
Good luck, it is a pretty straightforward script but I did not tidy it up at all. Cya next time!