My Quantified-Self Data Stack
Published January 26, 2024
Table of Contents
1. Why I collect data2. Cool self-insights I've found
3. My data stack
3.1 Browser Activity
3.2 Hard Drive Space
3.3 Physical Location
3.4 Smartwatch Biometrics
3.5 Music
3.6 Tweets
3.7 Purchasing data
3.8 Glucose
3.9 Air quality
3.10 Tetris (cognitive)
3.11 Stroop (cognitive)
3.12 Weight and grip strength
3.13 Dose times
4. Conclusion
4.1 Do it now!
4.2 Suggestions?
If you've ever wondered if you sleep worse after drinking coffee in the morning or how listening to music affects your focus, this post is for you. I used to have these musings, and now I just have the data to check for myself.
In this post I'm going to show y'all few self-insights I've derived from logging a lot of my personal data. I'll also list all the types of data and how they're collected.
Why I collect data
I think it's important to specify "why research" as well as "how research", and this "why" can become insincere when scientists court the big grant-writers in industry and government instead of saying what they really mean. I currently work for myself and will try to be a bit more honest — I like learning how my body and mind interact with my environment to create my lived experience. I also just like to know stuff.

Cool self-insights I've found
- My Ritalin blood concentration correlates with better Tetris performance
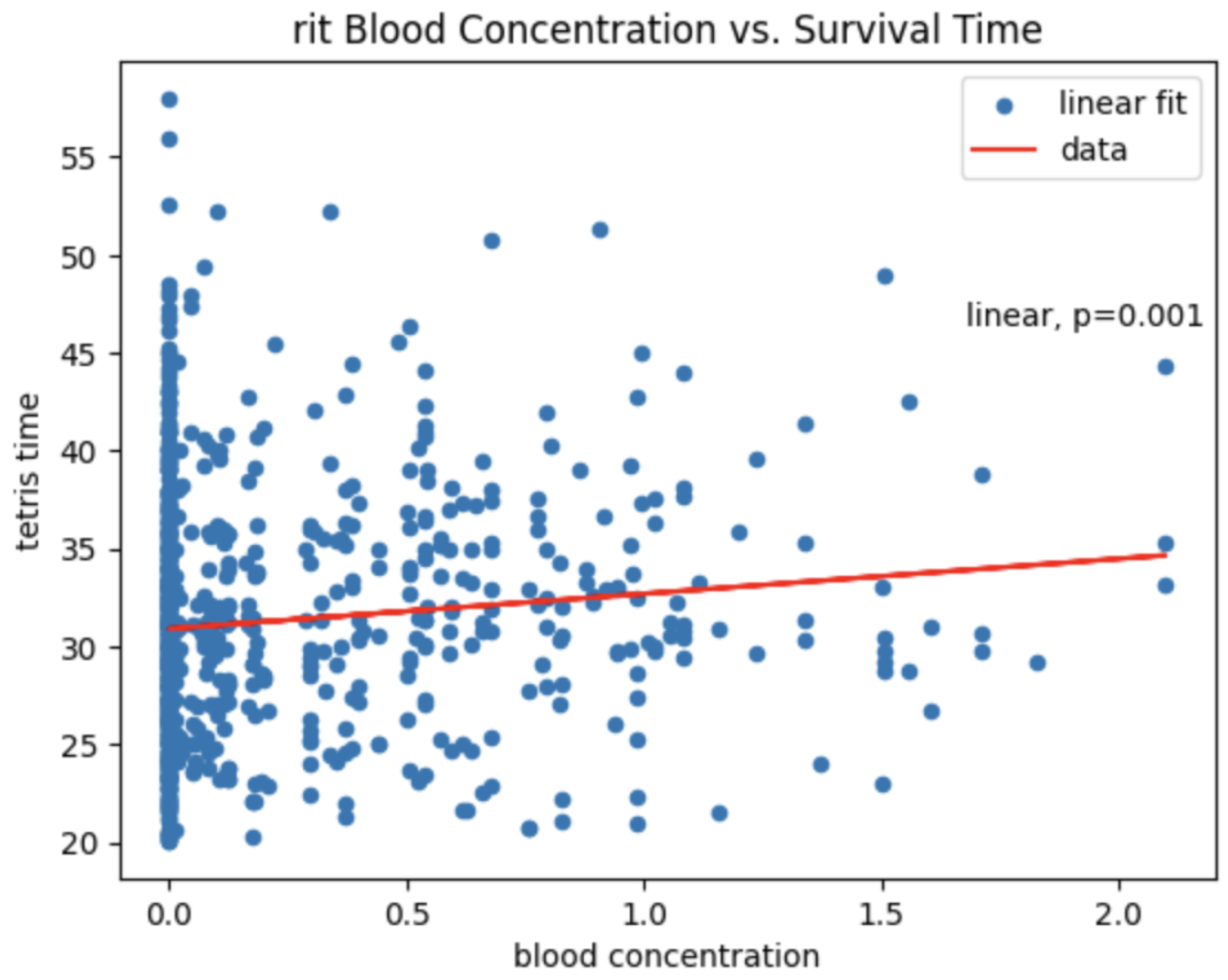
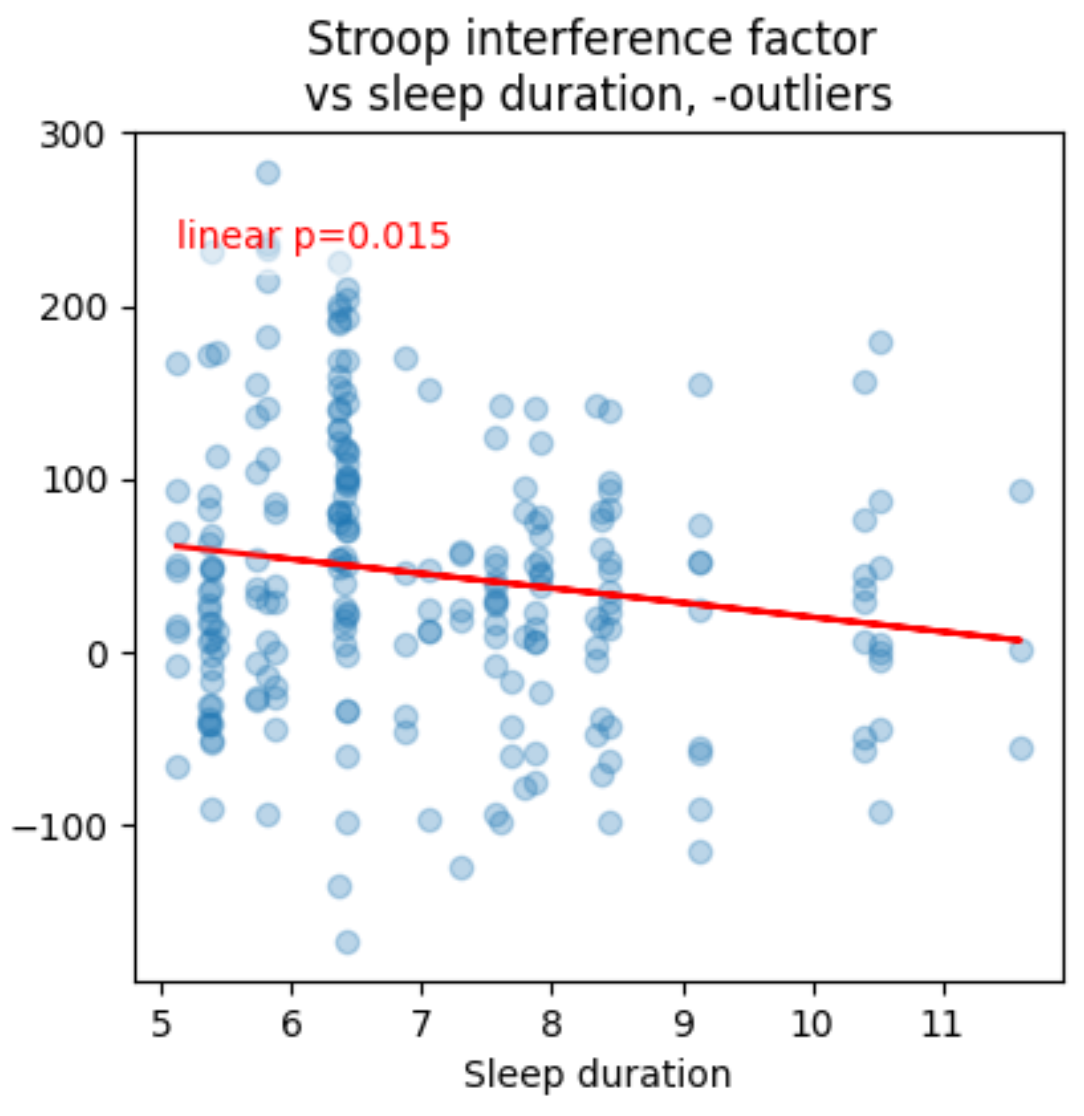
- I think better with more sleep (actually one of my most burning questions)
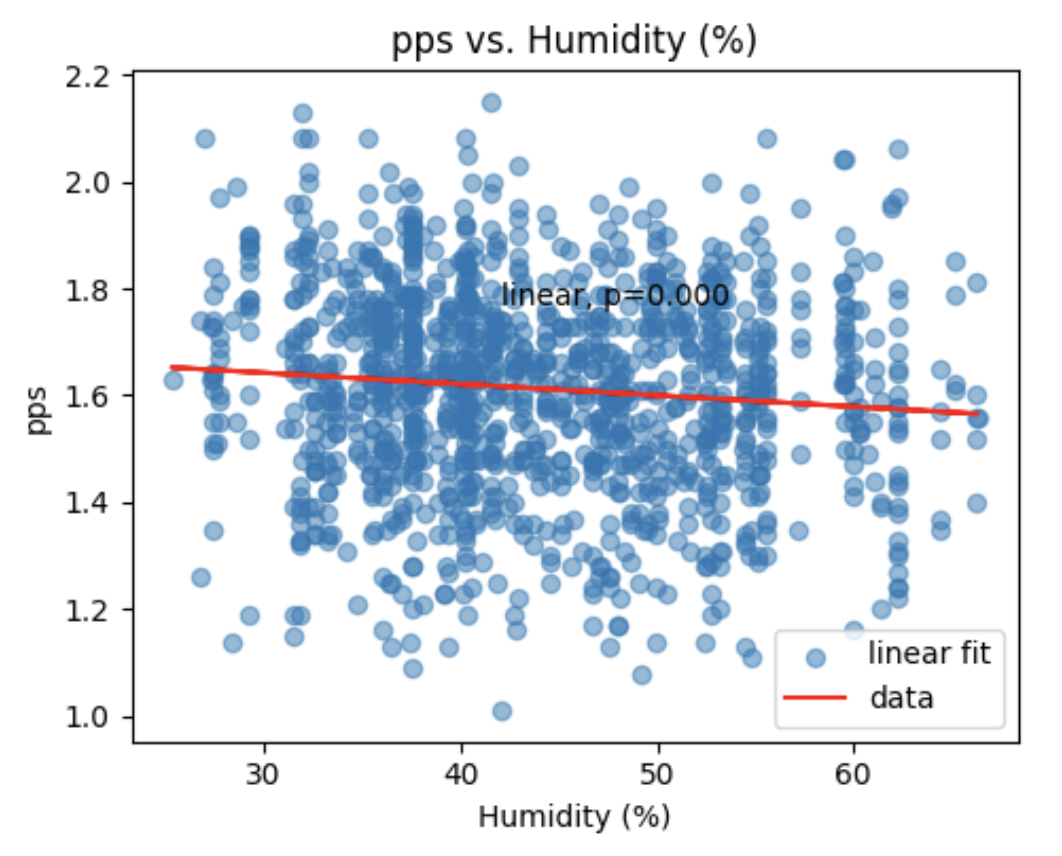
- My Tetris speed (pieces per second = PPS) correlates slightly with lower humidity
My data stack
Data that's useful for my analysis is either physical (heart rate, blood glucose, weight), mental (Tetris, Stroop), or environmental (air quality, music, location, computer activity). Data collection can be easy (hard drive space, Google location), or hard (computer activity), or just cost money (Fitbit, Spotify)
Not all the data is obviously useful — some of it is just easy to collect. But most data I expect to use as an 'x' or 'y' variable in some future analysis.
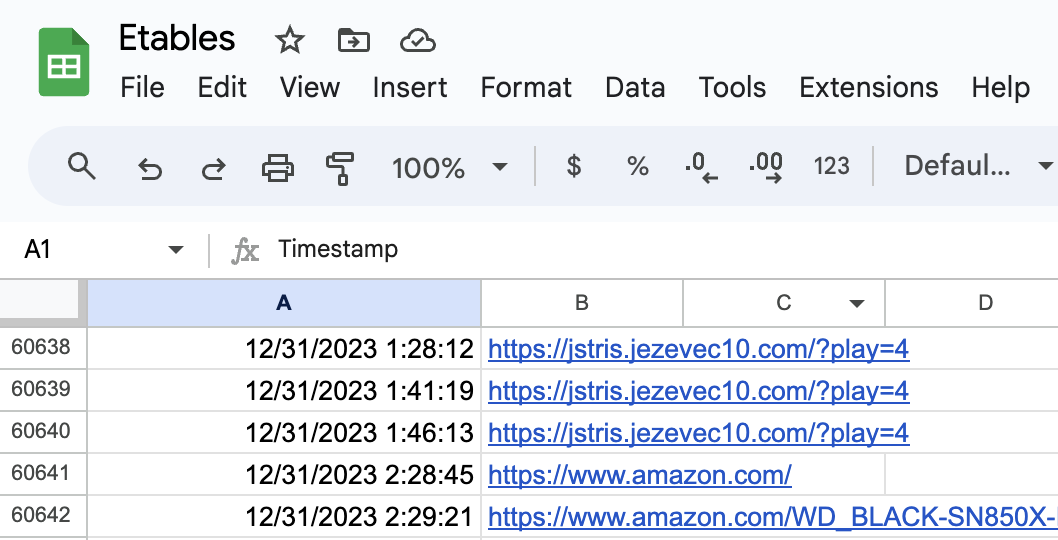
Browser Activity
Chrome websites visited with URL and timestamp. Collected via Tom Critchlow's JS electric tables script
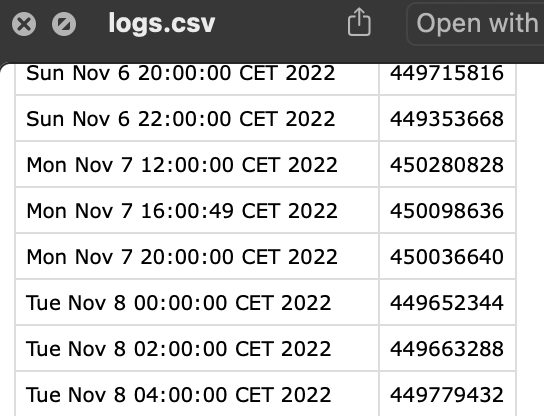
Hard Drive Space
Every 4 hours, a bash script logs my available hard drive space in bytes.
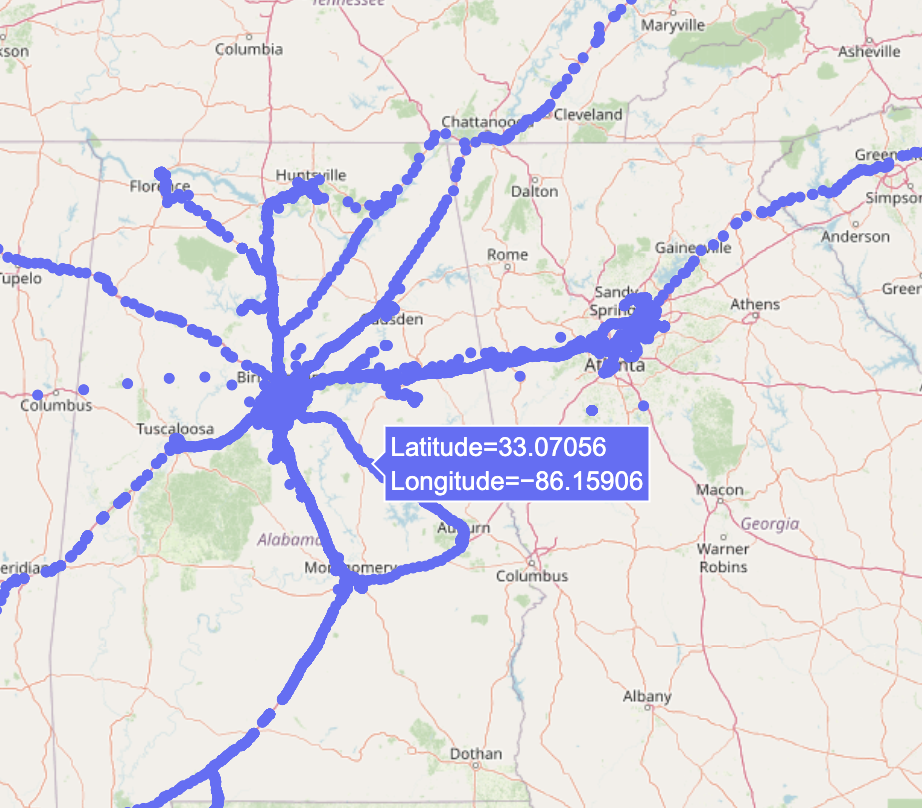
Physical Location
Google Maps Timeline is enabled on my phone and records my latitude/longitude every few minutes. I have this data going back a couple of years, and it includes the velocity and predicted mode of transport.
Smartwatch Biometrics
Fitbit records a ton of data and multiple granularities. There's tons of problems with the data itself (documented here and here ), but the majority is usable. Most usable stuff is probably the nightly sleep stats, minutely heart rate + HR variance, and daily step count. Fitbit offers this data export through the web interface
Music
Spotify! It's a bit complicated and I haven't looked into it, but all the streaming data is there. Spotify offers this data export through the web interface
Tweets
Twitter activity, has been used by ultimape to detect their shifting circadian rhythm, has been used by Andy for nothing so far. Twitter offers this data export through the web interface
Purchasing data
My Apple Card tracks all my purchases. The data is retrieved by manually hitting the "Export CSV" button on each month, and includes the Merchant and category and date.

Glucose
I wore a Freestyle Libre 2 CGM for two weeks and have nearly continuous data from that period (15-min intervals). Export is done through web interface.

Air quality
I use a QingPing air quality monitor to track my relative humidity, temperature, CO2, particulates (PM2.5), and tVOC (total volatile organic compounds). Through the QingPing IoT app, we can export the past year of data logged at 15-min intervals.

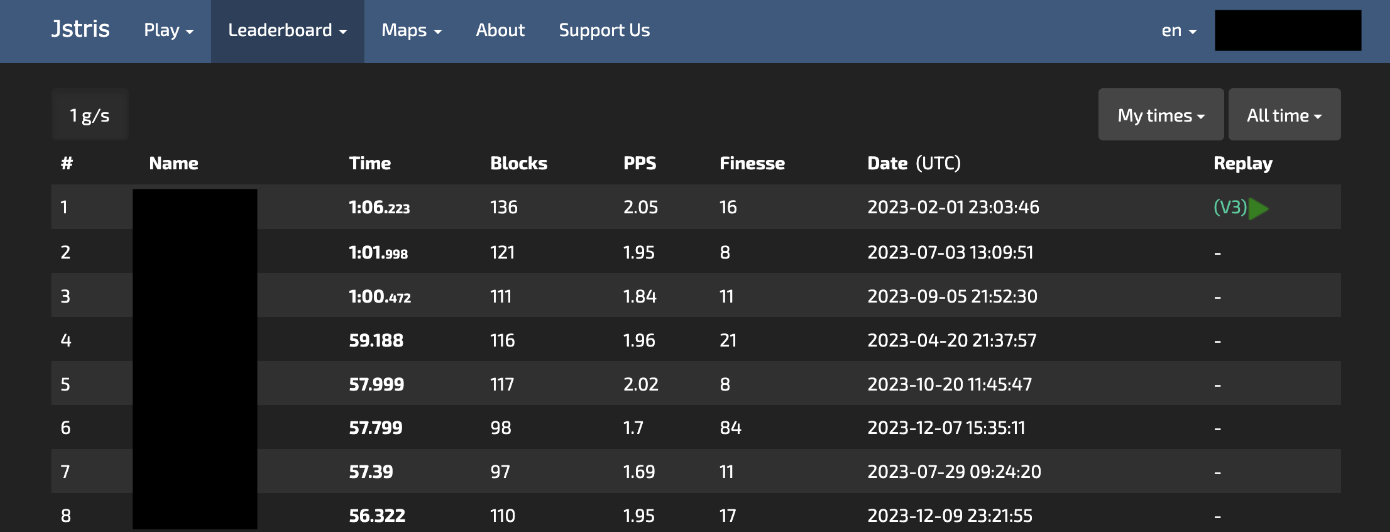
Tetris (cognitive)
I play Tetris for fun a few times a day. The website I play on records the stats and timestamps of each game, and I wrote a little Selenium scraper to retrieve it all. I run this every few months to collate all the data into a CSV.
Stroop (cognitive)
I use my Strooper chrome extension and complete a mini-Stroop test a few times a day. This gives me a coarse metric of my executive function, reading speed, and reaction time randomly throughout the day. I transfer the results into a spreadsheet monthly.

Weight and grip strength
Every night I record my weight and fat % with a bioimpedance scale, then record my left and right handed grip strength using a dynamometer. I record these as calendar events and transfer them to spreadsheets monthly.

Dose times
I frequently drink caffeinated beverages, sometimes use nicotine patches, and randomly try out OTC supplements like L-Theanine or magnesium. I update a calendar notebook with my dosage and time, and have gotten pretty good at just noting the time when I take them and logging it later. I transfer this to a spreadsheet every month or so.

Conclusion
Do it now!
Collecting personal data for long periods of time has compounding returns — you'll need to gather enough data points to average out daily fluctuations. So if you're reading this and even slightly curious — set up as many as possible ASAP! Storage is cheap, especially for single-user data like this, and in the worst case you can just delete it all. In the best case, you can know yourself a little better numerically!
Suggestions?
I hope this gives you some idea of the scope of data that can be collected for minimal effort on your part, and the potential cool graphs you can make from it. If you think of any neat relationships I should look for or other data I could collect, please DM and tell me!